Qwen2.5-Omni combine la vision, la parole et le langage dans un modèle en temps réel suffisamment petit pour les appareils périphériques.
Alibaba vient de lancer l’un de ses modèles d’IA les plus ambitieux à ce jour – et il n’essaie pas de gagner en étant le plus grand. Au contraire, Qwen2.5-Omni, un nouveau modèle multimodal à 7B paramètres, mise sur l’agilité, la polyvalence et les performances en temps réel pour le texte, l’image, l’audio et la vidéo.
Oui, il peut voir, entendre, parler et écrire. Et oui, il est suffisamment petit pour fonctionner sur un GPU grand public ou peut-être même sur votre téléphone. Ce n’est pas rien.
Le nouveau modèle, disponible en code source libre sous la licence Apache 2.0, est déjà en ligne sur Hugging Face, GitHub et d’autres plateformes. Il prend en charge les interactions en temps réel – y compris les chats vocaux et vidéo – et génère des réponses textuelles et vocales à la volée. Si vous avez toujours souhaité que ChatGPT puisse répondre avec moins de latence et plus de nuances, c’est peut-être le moment.
Penseur. Parleur. Allez-y.
Au cœur de Qwen2.5-Omni se trouve une nouvelle architecture qu’Alibaba appelle Thinker-Talker. Il s’agit d’une conception à double cerveau dans laquelle le « penseur » gère la perception et la compréhension – en analysant l’audio, la vidéo et les images – tandis que le « locuteur » transforme ces pensées en un discours ou un texte fluide et en continu.
Il est conçu pour une interaction multimodale de bout en bout, ce qui signifie qu’il n’a pas besoin de convertir la voix en texte avant de comprendre ou de penser. Il traite tout cela en mode natif et en parallèle.
Pour gérer les médias sensibles au temps comme la vidéo et l’audio, Alibaba a également introduit TMRoPE, une nouvelle façon de synchroniser le temps entre les modalités. Cela lui permet de faire des choses comme des réponses synchronisées sur les lèvres ou de répondre plus précisément à des questions sur des images en mouvement.
Minuscule, mais puissant
Ce qui est surprenant, c’est tout ce que Qwen2.5-Omni contient dans seulement 7 milliards de paramètres, ce qui est peu par rapport aux normes LLM actuelles. À titre de comparaison, le LLaMA 3 de Meta devrait atteindre 140 milliards de paramètres. Mais le modèle d’Alibaba est conçu pour fonctionner sur des machines plus petites sans sacrifier trop de capacités.
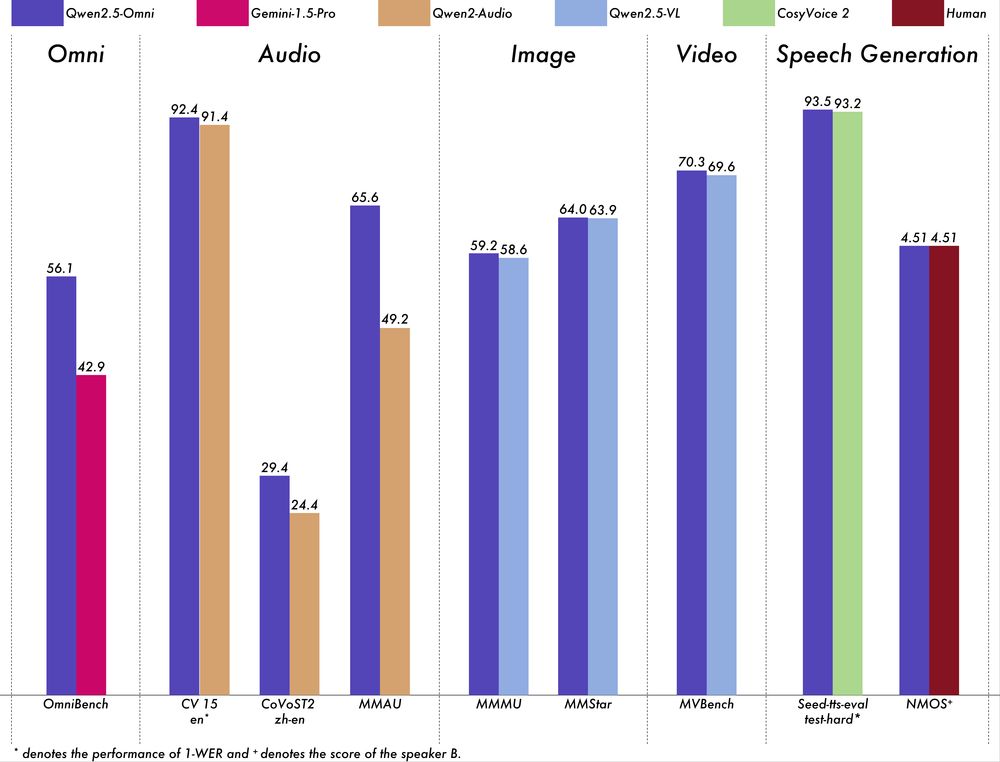
Et les performances ? Solides. Qwen2.5-Omni bat le propre modèle audio d’Alibaba (Qwen2-Audio), tient tête à son modèle visuel (Qwen2.5-VL) et rivalise même avec des poids lourds fermés comme Gemini 1.5 Pro dans le raisonnement multimodal.
Les tests montrent qu’il excelle dans la reconnaissance vocale (Common Voice), la traduction (CoVoST2) et même dans les tests de compréhension vidéo difficiles comme MVBench. Il est particulièrement performant dans la génération de parole en temps réel, ce qui est délicat pour les petits modèles.
La démocratisation de l’IA multimodale
La taille compacte de Qwen2.5-Omni pourrait avoir des implications majeures pour l’adoption de l’IA. Contrairement aux grands modèles qui nécessitent une infrastructure cloud coûteuse, ce modèle pourrait fonctionner sur des appareils du quotidien. Imaginez des assistants IA capables d’interagir naturellement avec vous via la caméra et le microphone de votre ordinateur portable, sans nécessiter de connexion constante à des serveurs distants.
Cette approche « edge computing » (traitement en périphérie) pourrait également résoudre certains problèmes de confidentialité, puisque les données sensibles n’auraient pas besoin de quitter l’appareil de l’utilisateur. C’est particulièrement pertinent dans des domaines comme la santé ou l’éducation, où la confidentialité est primordiale.
Applications concrètes et cas d’usage
Les applications potentielles de Qwen2.5-Omni sont vastes. Dans l’éducation, il pourrait servir de tuteur personnel capable de voir les exercices d’un étudiant, d’écouter ses questions et d’y répondre vocalement avec des explications personnalisées. Dans le commerce électronique, il pourrait permettre des assistants d’achat qui comprennent visuellement les produits que vous leur montrez et répondent à vos questions en temps réel.
Pour les personnes âgées ou malvoyantes, ce type de modèle pourrait offrir une assistance plus naturelle et accessible. Imaginez un appareil qui peut décrire vocalement ce qu’il « voit » ou qui peut lire et expliquer des documents imprimés sans délai perceptible.
Les développeurs pourraient également exploiter cette technologie pour créer des interfaces homme-machine plus intuitives, où l’ordinateur comprend non seulement ce que vous dites, mais aussi votre langage corporel et vos expressions faciales.
Défis et limitations
Malgré ses performances impressionnantes, Qwen2.5-Omni fait face à des défis. Sa taille réduite implique inévitablement certains compromis en termes de capacités. Les modèles plus grands comme GPT-4o ou Claude 3 Opus disposent d’une base de connaissances plus vaste et d’une meilleure compréhension nuancée dans certains domaines complexes.
La consommation d’énergie reste également un défi pour l’exécution en continu sur des appareils mobiles, même avec un modèle de cette taille. Et comme tous les modèles d’IA, des questions se posent concernant les biais potentiels dans ses réponses et sa robustesse face à des entrées malveillantes.
Le futur des modèles multimodaux compacts
L’approche d’Alibaba avec Qwen2.5-Omni s’inscrit dans une tendance plus large vers des modèles d’IA plus efficaces. Plutôt que de simplement augmenter la taille des modèles, les chercheurs se concentrent de plus en plus sur l’optimisation de l’architecture et des techniques d’entraînement pour obtenir plus avec moins.
Cette direction pourrait être particulièrement importante dans les régions du monde où l’accès à une puissance de calcul importante est limité. Des modèles comme Qwen2.5-Omni pourraient aider à réduire la fracture numérique en rendant les technologies d’IA avancées accessibles sur du matériel plus abordable.
À mesure que ces modèles continuent d’évoluer, nous pourrions voir une nouvelle génération d’applications d’IA qui s’intègrent de manière transparente dans notre vie quotidienne, capables de nous voir, de nous entendre et de nous parler sans les barrières traditionnelles de l’interface utilisateur.
Pour les développeurs et les entreprises cherchant à intégrer des capacités multimodales dans leurs produits sans les coûts prohibitifs des grands modèles, Qwen2.5-Omni représente une option prometteuse à surveiller de près dans les mois à venir.
Partager la publication "La nouvelle IA d’Alibaba Qwen voit, entend et parle en temps réel"
Nous utilisons des cookies pour vous garantir la meilleure expérience sur notre site. Si vous continuez à utiliser ce dernier, nous considérerons que vous acceptez l'utilisation des cookies.